






Grass:第一个第2层数据汇总
在过去的几周里,我们一直在发布内容来解释Grass在AI堆栈中的作用。如您所知,该协议执行许多功能,帮助构建者访问web数据来训练他们的模型。这是人工智能管道至关重要的第一阶段,也是所有开发的起点。
在格拉斯的案例中,世界各地的住宅设备承载着一个节点网络,这些节点从网络上收集并处理原始数据。它将这些数据清理并转换为结构化数据集,以用于人工智能训练。最重要的是,它收集网络数据的方式涉及并回报了全球近百万人的参与。它一手创建了人工智能数据供应类别,这也是世界上一些最大的人工智能公司选择与我们合作的原因。它是人工智能的数据层.
与此同时,我们也在过去几周反思了人工智能的现状。我们问自己它面临的最紧迫的问题,以及作为人工智能基础设施的一个突出部分,我们可以做些什么来解决这些问题。
我们的结论是,目前人工智能领域最大的问题是缺乏数据透明度。看一眼新闻就会知道为什么。问问你自己,为什么一个人工智能模型把埃隆·马斯克等同于希特勒?或者抹去整个民族世界历史上的?它是用坏数据训练的吗?或者更糟,有了好的数据选择性选择给出不好的答案?
答案是,我们不知道。我们不知道是因为决不要知道。我们不知道这些模型是根据什么数据训练的,因为没有机制可以证明这一点。用户没有办法验证数据来源,因为构建者没有办法自己验证。
这是Grass计划解决的问题,我们现在正在构建一个layer 2数据汇总来解决它。你可能会问,怎么做?
请允许我们解释。
第二层如何建立数据来源
世界需要一种方法来证明人工智能训练数据的来源,这就是Grass现在正在建立的方法。很快,每次Grass节点抓取数据时,都会记录元数据以验证数据是从哪个网站抓取的。这些元数据将永久嵌入每个数据集中,使构建者能够完全确定地了解其来源。然后,他们可以与用户分享这种血统,用户可以放心地知道,他们与之交互的人工智能模型没有被故意训练为给出误导性答案。
这将是一个巨大的提升,并涉及我们协议的重大扩展,因为我们准备让抓取操作达到每分钟数千万个web请求。其中每一项都需要验证,这将需要比任何L1都多的吞吐量。这就是为什么我们宣布计划构建一个第2层解决方案来处理我们能力的重大升级。L2将是一个主权汇总,采用ZK处理器,以便元数据可以进行批量验证,并用于为我们生成的每个数据集提供持久血统。这是所有人工智能开发的基础层进入下一阶段所需要的。
这样做的好处很多:它将打击数据中毒,增强开源人工智能的能力,并为用户了解我们每天交互的模型开辟一条道路。
下面,我们将描述系统的基本设计。
Grass系统结构
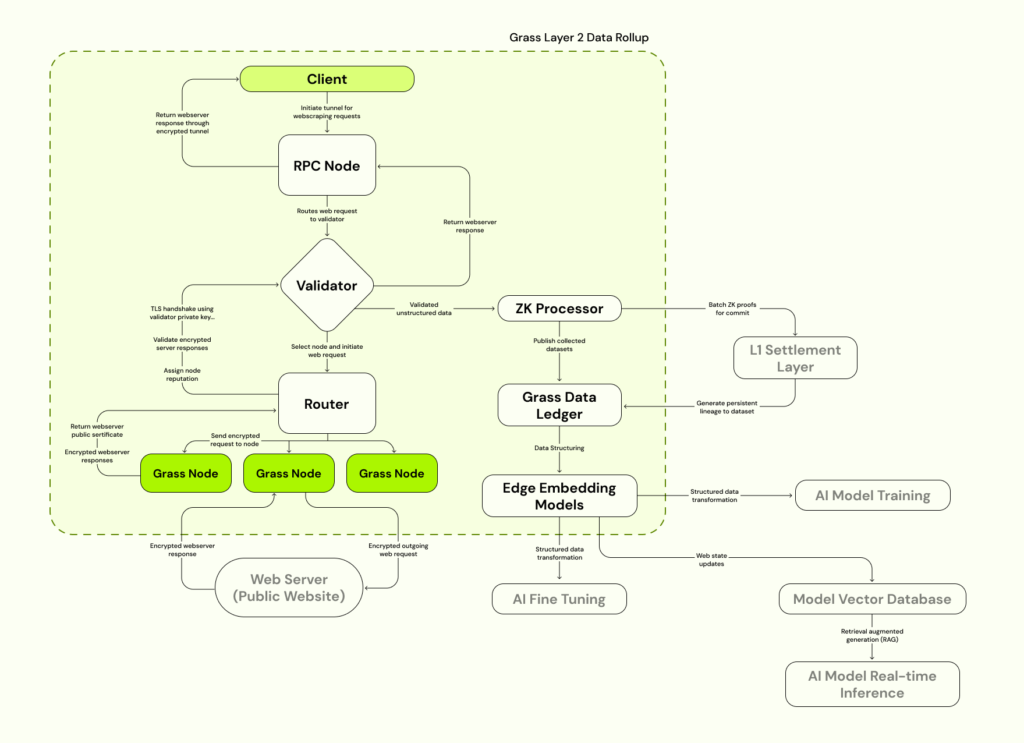
了解这些升级的最简单方法是查阅Grass数据汇总图。在左侧,在客户端和Web服务器之间,您可以看到传统定义的Grass网络。客户端发出web请求,这些请求通过验证器发送,最终通过Grass节点路由。无论客户端请求哪个网站,其服务器都会对web请求做出响应,允许其数据被抓取并发送回网络。然后,它将被清洗、处理并准备用于训练下一代人工智能模型。
回到L2图,您将在右侧看到两个主要的新增功能,它们将伴随着Grass第二层主权的推出:Grass数据分类账和ZK处理器。
每一个都有自己的功能,所以我们一次解释一个。
Grass数据分类账
草地数据分类账是所有数据的最终存储地。它是在草地上收集的每个数据集的永久分类账,现在嵌入了元数据以记录其从起源时起的血统。每个数据集的元数据的证明将存储在Solana的结算层上,结算数据本身也将通过分类账提供。重要的是要注意Grass有一个地方来存储它抓取的数据的重要性,尽管我们很快就会谈到这一点。
ZK处理器
如上所述,ZK处理器的目的是帮助记录在Grass网络上收集的数据集的来源。想象一下这个过程。
当网络上的一个节点(换句话说,一个具有Grass扩展名的用户)向给定网站发送web请求时,它会返回一个加密响应,其中包含该节点请求的所有数据。对于所有意图和目的,这是我们的数据集诞生的时候,这是需要记录的起源时刻。
这正是记录元数据时捕捉到的瞬间。它包含许多字段-会话密钥、抓取的网站的URL、目标网站的IP地址、交易的时间戳,当然还有数据本身。这是所有必要的信息,可以毫无疑问地知道给定的数据集来自它声称来自的网站,因此给定的人工智能模型得到了正确而忠实的训练。
ZK处理器进入等式,因为这些数据需要在链上结算,但我们不希望所有这些数据对Solana验证器可见。此外,有一天将在Grass上执行的web请求的绝对数量将不可避免地超过任何L1的吞吐能力-即使是像索拉纳这样有能力的人。Grass将很快扩展到每分钟执行数千万个web请求的程度,每个请求的元数据都需要在链上处理。在没有ZK处理器首先进行证明和批处理的情况下,将这些事务提交给L1是不可能的。因此,L2是实现我们既定目标的唯一可能方式。
为什么这是一件大事呢?
第二层优势
数据分类账
数据分类账意义重大,因为它将Grass的扩张升级为一种额外的-而且是根本不同的-商业模式。虽然该协议将继续审查那些发送自己的网络请求并在网络上收集自己数据的买家,但其活动中越来越多的部分将涉及已经存储在分类账上的数据。有了这一功能,Grass现在可以收集战略上精心策划的数据以用于LLM培训,并将其托管在不断扩大的数据存储库中。
这个存储库是模块化AI堆栈的数据层,构建者可以从中挑选组成部分来训练无限差异化的模型。它是互联网本身的缩影,提供已经结构化并准备好被人工智能摄取的训练数据。
ZK处理器
我们已经详细介绍了ZK处理器的重要性。通过使我们能够创建记录Grass数据集来源的元数据的证据,它为构建者和用户创建了一种机制来验证人工智能模型是否确实得到了正确的训练。这本身就是一件大事。
然而,有一件事我们之前没有提到。
除了记录数据集来源的网站之外,元数据还表明网络上的哪个节点它是通过。值得注意的是,这意味着每当一个节点抓取网页时,他们都可以因其工作而获得信用,而不会泄露任何有关他们自己的身份信息。
为什么这很重要?
这很重要,因为一旦你可以证明哪些节点完成了哪些工作,你就可以开始按比例奖励它们。有些节点比其他节点更有价值。有些人比同龄人收集了更多的数据。这些是精确地我们需要激励的节点继续我们在过去几个月看到的网络的飞速扩展。我们相信,这一机制将大大提高全球最受欢迎地区的奖励,最终鼓励这些地区的人们注册并成倍增加网络容量。
不言而喻,网络变得越大,我们需要收集的容量就越大,存储的网络数据也就越多。飞轮将不可避免地产生,更多的数据意味着我们将有更多的数据提供给需要训练数据的人工智能实验室-从而为网络的持续发展提供动力。
结论
总而言之,当今人工智能的大多数高调问题都源于缺乏对模型训练方式的可见性,我们相信这可以通过为开源人工智能提供一个验证数据来源的系统来解决。我们的解决方案是构建有史以来第一个第2层数据汇总,这将使引入记录所有数据集来源的元数据的机制成为可能。
这些数据的ZK证明将存储在L1结算层,元数据本身最终将与其底层数据集绑定在一起,因为这些数据集本身存储在我们自己的数据分类账上。Grass为模块化AI堆栈提供了数据层,这些开发将为节点提供商实现更大的透明度和与其执行的工作量成比例的回报奠定基础。
这次更新应该有助于沟通我们即将开展的一些项目,并阐明推动我们决策的思路。我们很高兴能在使人工智能更加透明方面发挥作用,并很高兴看到我们的产品将出现许多用例。这些升级将为开发人员带来广泛的机会,因此如果您或您的团队对在Grass上进行开发感兴趣,请联系我们。感谢您的支持,敬请关注。
您好,这是一条评论。若需要审核、编辑或删除评论,请访问仪表盘的评论界面。评论者头像来自 Gravatar。