






Grass是人工智能的数据层
Grass是一个用于访问公共网络的去中心化网络,因此可以访问训练AI模型所需的数据。随着它扩展到清理和准备结构化数据集的业务中,它成为人工智能存在的基础不可或缺的一部分-人工智能的数据层。
介绍
最近,你可能听到人们将Grass称为“人工智能的数据层”。那是什么意思呢?
你可能已经意识到,就在我们说话的时候,人工智能革命正在展开,你可能知道在还有时间的情况下,种草是最容易获得股份的方式。但任何比这更复杂的事情,嗯,这就是头疼的开始。这个主题变得复杂得很快,而且有很多噪音。
这没关系。解释这些东西是我们的工作。
因此,今天我们将更详细地介绍人工智能的数据层,并解释Grass最近开始执行的一些新服务。然后你会更清楚地了解为什么60万人似乎认为这是一个好主意,以及为什么你决定加入是一个正确的选择。让我们开始吧。
- AI的数据层是什么?
AI的数据层是什么?
好吧,在我们开始之前,人工智能首先是什么?像5岁小孩一样解释。
简单地说,AI是一个程序,它获取大量数据并从中找到模式。然后,当出现提示时,它使用这些模式进行预测。
举个例子:想想ChatGPT。它需要数十亿个单词,并注意它们之间的相互联系。它在“蓝色”这个词旁边看到“天空”这个词10次或15000次,现在它可以告诉你:天空是蓝色的。
好了,现在暂停。
你会注意到那一段发生了三件事。
首先,模型获取了要训练的数据。其次,它通过梳理来“学习”它能找到的所有模式和相关性。第三,当你问天空是什么颜色时,它告诉你“蓝色”。
当你想到人工智能协议时,尤其是在加密领域,你可能会想到第二部分——训练。你会想到模型在梳理数据、寻找模式时使用的分散式处理器网络。你是对的——这是一种人工智能协议。问题是,这不是最重要的部分。不过,下一部分要仔细阅读。
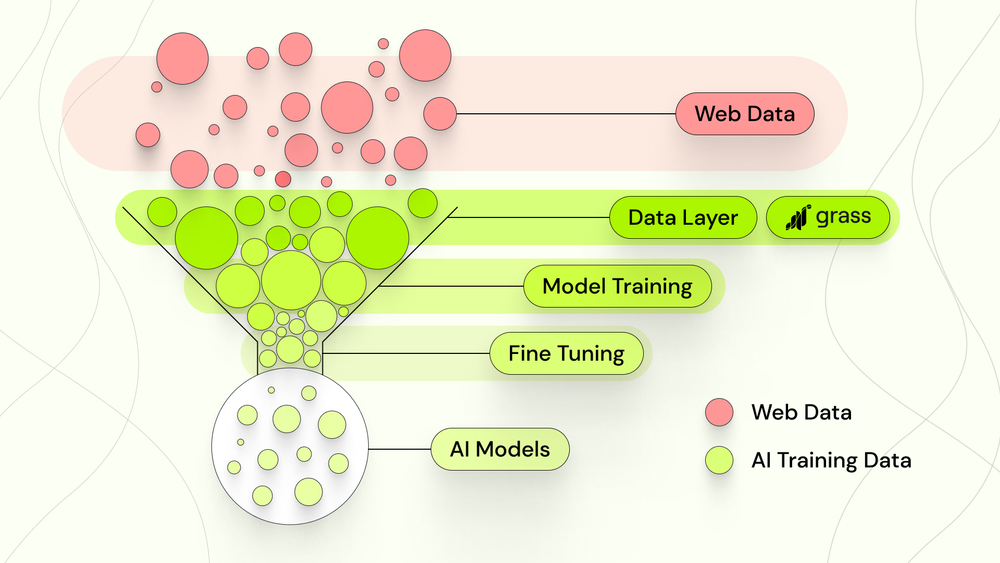
虽然训练一个人工智能模型显然很重要,但你使用它时得到的答案是有基础的只,仅仅它在训练数据中发现的相关性。ChatGPT可以告诉你天空是蓝色的仅仅因为它在接受训练的数据中遇到这个答案的次数够多了。如果你从低质量的训练数据开始,你最终会得到低质量的答案。没有训练数据?没有答案。
换句话说,你可以拥有地球上最强大的模型,但如果它是在两篇都说天空是绿色的中等文章上训练的,猜猜当你问天空是什么颜色时,你的模型会告诉你什么。Bzzzt。回答错误。
从这个角度来看,数据实际上是任何人工智能模型中最重要的部分。数据绝不是开发的敷衍前言,它实际上是任何功能模型的核心,数据供应是任何培训的基础。这就是为什么,根据一份报告,“为人工智能工具准备数据通常占多达百分之八十在实施人工智能系统的总工作量中。“数据资源调配实际上是大部分工作!
那么什么是数据层呢?
数据层是人工智能发展第一阶段。这是人工智能堆栈的一部分,在训练开始之前就为模型收集和准备数据。朋友们,这是草。这也是你可以做出贡献的地方,也是你可以从寒武纪人工智能大爆发中获得一些好处的地方。所以一定要和我们在一起。让我们继续…
- Grass是否用于获取AI训练所需的数据?
我们很高兴你问了。是的,这正是草的用途!
当你在Grass上运行一个节点时,你出售的是你的互联网连接中没有使用的部分。我们并不是每天24小时都在播放视频,所以有很多你付费使用的互联网,但在任何给定的时间都不会使用。
而这是人工智能实验室将为之付费的资源!使用我们的网络,他们可以上网查看公共网站并收集人工智能数据。然后将其用于训练目的,创建未来的人工智能模型,并补偿普通人的变化。真的就这么简单。
- 从互联网上收集数据后,Grass是否用于准备这些数据?
多亏了Socrates,我们新的内部人工智能垂直开发,确实如此。
当数据从公共网站上抓取时,它是非结构化的。想象一下网站上的语言数据,你看到的不是句子和段落,而是一串数千位数的字母和数字,没有可理解的顺序。结构化数据指的是获取这些数字并将其转换为可识别格式的过程-在本例中,对它们进行组织以便它们实际上可以被读取和解释。数据需要以特定的方式结构化,以便人工智能模型使用它,因此这显然是人工智能管道中的关键一步。
准备工作的另一个组成部分是清理数据。离群值可能会扭曲模型在学习时得出的结果,因此在训练开始前将其剔除非常重要。此外,我们开始看到越来越多的故意投毒事件数据战争升温和公司试图破坏对方。他们通过在网站上故意发布虚假信息来实现这一目标,以便在对手试图从对方那里获取企业情报时阻止他们.这是为什么数据不能在没有事先仔细准备的情况下简单地插入人工智能模型的又一个原因。
Socrates最初是一个大型数据库,人工智能实验室可以请求访问该数据库,专门用于培训LLM。然而,目前正在进行的工作是训练一个自己的模型,用于自动收集和准备数据的过程,以及在收集数据后标记数据。这将真正推动数据层加速发展,全面加速去中心化人工智能的进步。
- 为什么执行这些服务需要分散式网络?
许多现存的最大网站都与私营、集中化的人工智能公司有利害关系,并在防止较小的竞争对手站稳脚跟方面有既得利益。即使是那些还没有开始意识到他们的数据价值的公司,也已经开始制定政策,使除了最大的人工智能实验室之外的所有公司都无法获得数据。例如,可以从Reddit获取大量语言数据,但该公司去年开始对其API收取过高的费用,现在试图阻止人们自己抓取这些数据。
实际上,这通常是通过封锁已知数据中心的IP地址来实现的。许多公司运行像Grass这样的网络,与Grass的分散和公平设计相比,这些网络是集中和提取的,并且这些网络通常依赖数据中心进行收集。由于网站会屏蔽这些IP地址,人工智能实验室能够查看它们的唯一真正方式是通过Grass这样的去中心化网络。
- Grass如何优于传统的数据供应方法?
Grass的建立只有一个原因:因为人工智能的兴起是纠正Web 2.0中一些错误的机会。我们对互联网目前的发展方式感到不满,我们相信建立这种基础设施是在Web3的发展中推广我们价值观的最佳方式。
以下是我们引以为豪的三件事:
- Grass是一个将由其用户拥有和运营的网络。当你运行一个节点并获得积分时,你在帮助运营网络的同时也获得了网络本身的股份。与其他网络不同的是,Grass旨在成为一个公平的集体项目,如果它们真的激励用户的话,只会以微薄的报酬激励他们。这意味着随着人工智能的发展,我们所有人都会受益,而不仅仅是比尔·盖茨和埃隆·马斯克。
- 对于任何人来说,种草是目前了解人工智能兴起的唯一最简单的方式。运行节点就像注册和安装Chrome扩展一样简单,应用程序会为您完成其余工作。Grass是一种被动而非主动的参与人工智能的方式,这意味着任何人都可以几乎不费吹灰之力就做出贡献。
- 除了在训练传统人工智能方面的有用性外,Grass还通过为访问网络数据创建替代路径来实现去中心化和开源人工智能的创建。如果没有人这样做,像谷歌和微软这样的公司将被授权守门公共网站,作为唯一对整个事件进行索引的实体。然后,他们可以利用这种权力对人工智能的发展进行垄断,因为(正如你现在所知道的)没有训练数据=没有人工智能模型。通过提供这项服务并创建像Socrates那样的结构化数据的rails,Grass正在努力使所有人都可以访问公共web数据。
这是很多信息,但希望你对Grass在人工智能开发中扮演的角色有更好的了解,我们当前的任务是什么,以及为什么我们觉得它如此重要。通过参与我们的活动,您不仅仅是在为网络建设工作赚取报酬。你在帮助创造一个更美好、更公平、更公正的世界。就像AI本身一样,这一切都始于数据层。因此,感谢你们帮助我们建设基础设施,创造我们想要生活的世界。
在人工智能革命中获利。